library(tidyverse)
library(thematic)
# add other packages, if anyI got this data from tidy tuesday on github
tidytuesday/data/2022/2022-11-01 at master · rfordatascience/tidytuesday (github.com)
Data
The dataset is about horror movies and their genres and popularities. I chose this dataset because i’ve been wanting to watch horror movies but i didn’t know which ones were interesting or considered good.
Packages
Which packages will you be using and for what purpose?
I will be using the tidyverse package for data wrangling and visualization, i will also be using the janitor package for initial cleaning.
Explorations
The explorations were unexpected what i found there’s movies that when they first came out i thought they did bad in the box office but here those movies are being some of the best.
horrordf <- read.csv("horror_movies.csv")
# add code to read dataWhat movie made the most money?
It looks like “IT” is the horror movie that made the most money but since on the first line of codes list there’s movies there that aren’t really scary and more on the thriller side,i then did a second exploration and filtered the data by the horror genre and found that the scariest movie that made the most money in that genre is “The Exorcist”.
horrordf |>
select(title,revenue) |>
arrange(desc(revenue)) |>
head() |>
ggplot(aes(x = title, y = revenue)) +
geom_bar(stat = "identity")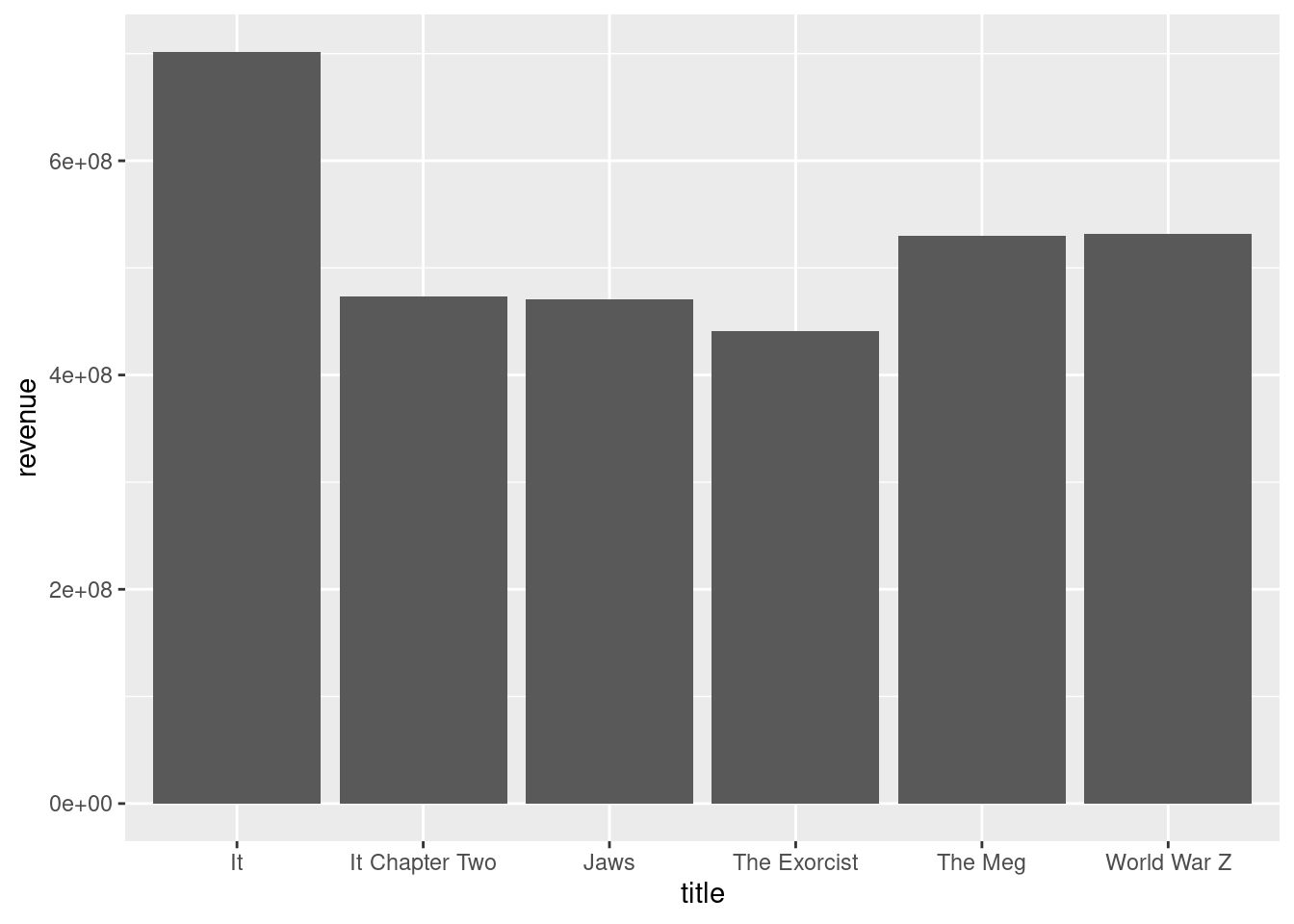
horrordf |>
select(title,revenue,genre_names) |>
filter(genre_names %in% c("Horror")) |>
arrange(desc(revenue)) |>
head() |>
ggplot(aes(x = title,y = revenue)) +
geom_bar(stat = "identity", fill = "#104E8B") +
labs(title = "Top 6 Horror Movies", subtitle = "In The Horror Genre") +
theme_dark()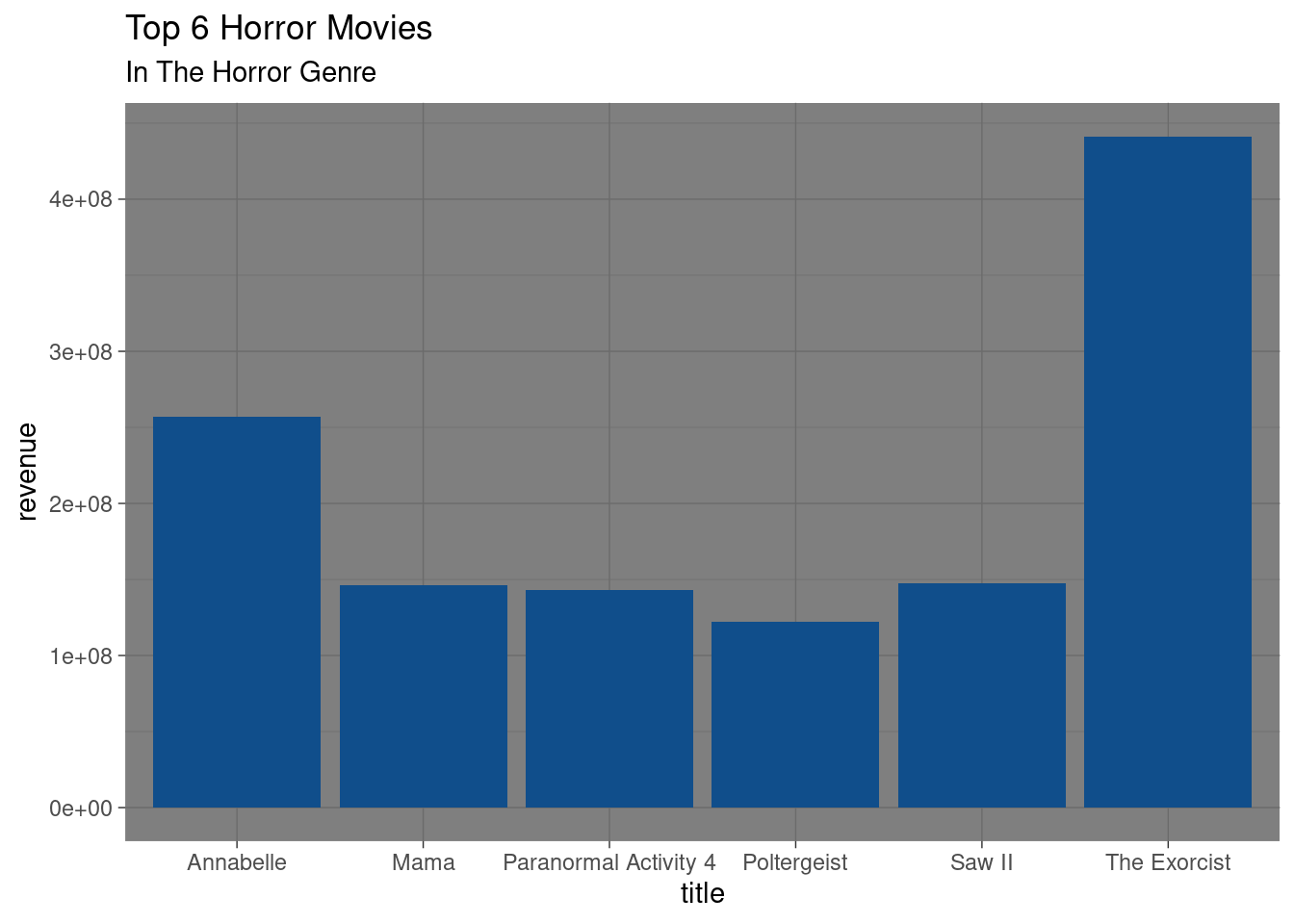
Which movies are the most popular?
After seeing whats popular this shows that the movies that make the most money aren’t necessarily popular.However I don’t know what the popularity scale goes off of.So im going to compare the revenue and popularity in a scatterplot.After looking at the scatterplot the most popular movie didn’t really make money so i would initially take the movies that made money over popularity.
horrordf |>
select(title,popularity,genre_names) |>
arrange(desc(popularity)) horrordf |>
ggplot(aes(x = revenue, y = popularity)) +
geom_point()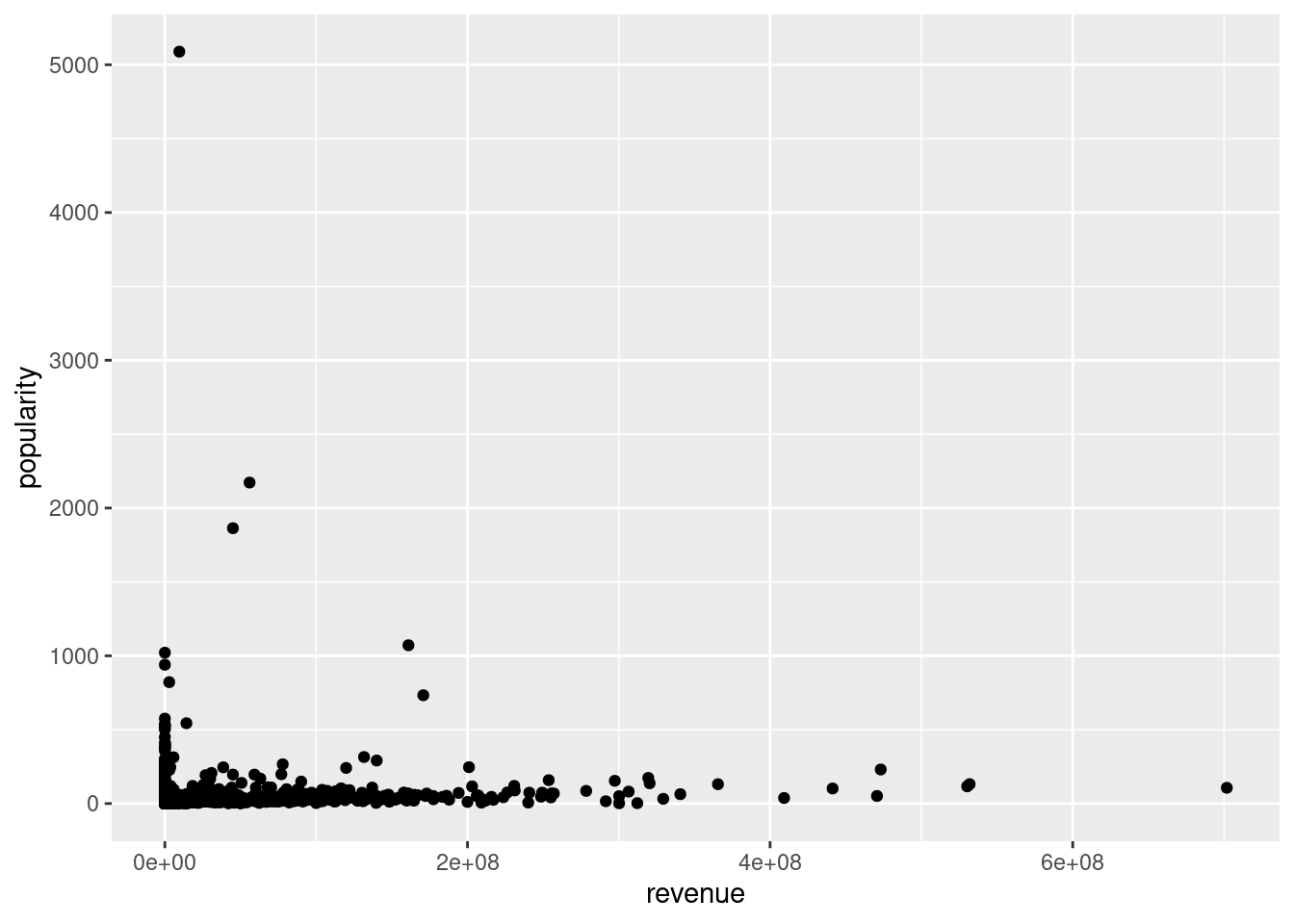
For the movies that made a lot of revenue,did they have a large budget?
I want to know if the budget has something to do with a movie being popular or making a large amount of revenue.
Having a large budget doesn’t necessarily mean anything some movies have low budgets but become box office hits for example “IT” having a 35 million dollar budget but then made over 700 million in the box office, while a movie like world war z had a 200 million dollar budget and then made 530 million dollars in revenue.
horrordf |>
select(title, budget, revenue) |>
arrange(desc(revenue)) |>
top_n(20) |>
ggplot(aes(x = title, y = revenue, color = budget)) +
geom_point() +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust=1)) +
labs(title = "")Selecting by revenue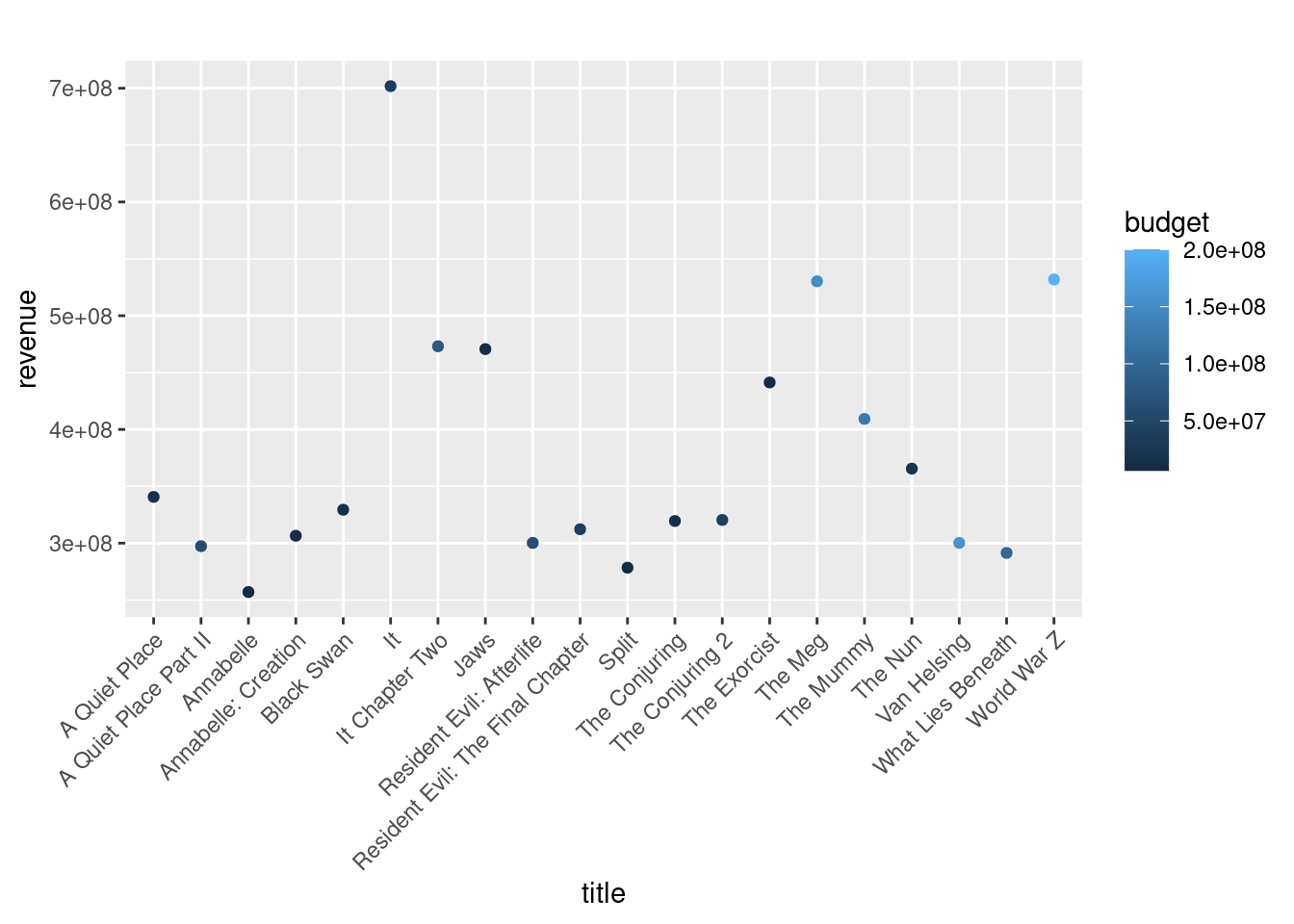
Discussion
Summary of findings on the data and what you learned in the process about the data context as well as about using R.