Conclusion
Write up your thoughts about this data science project here and answer the following questions:
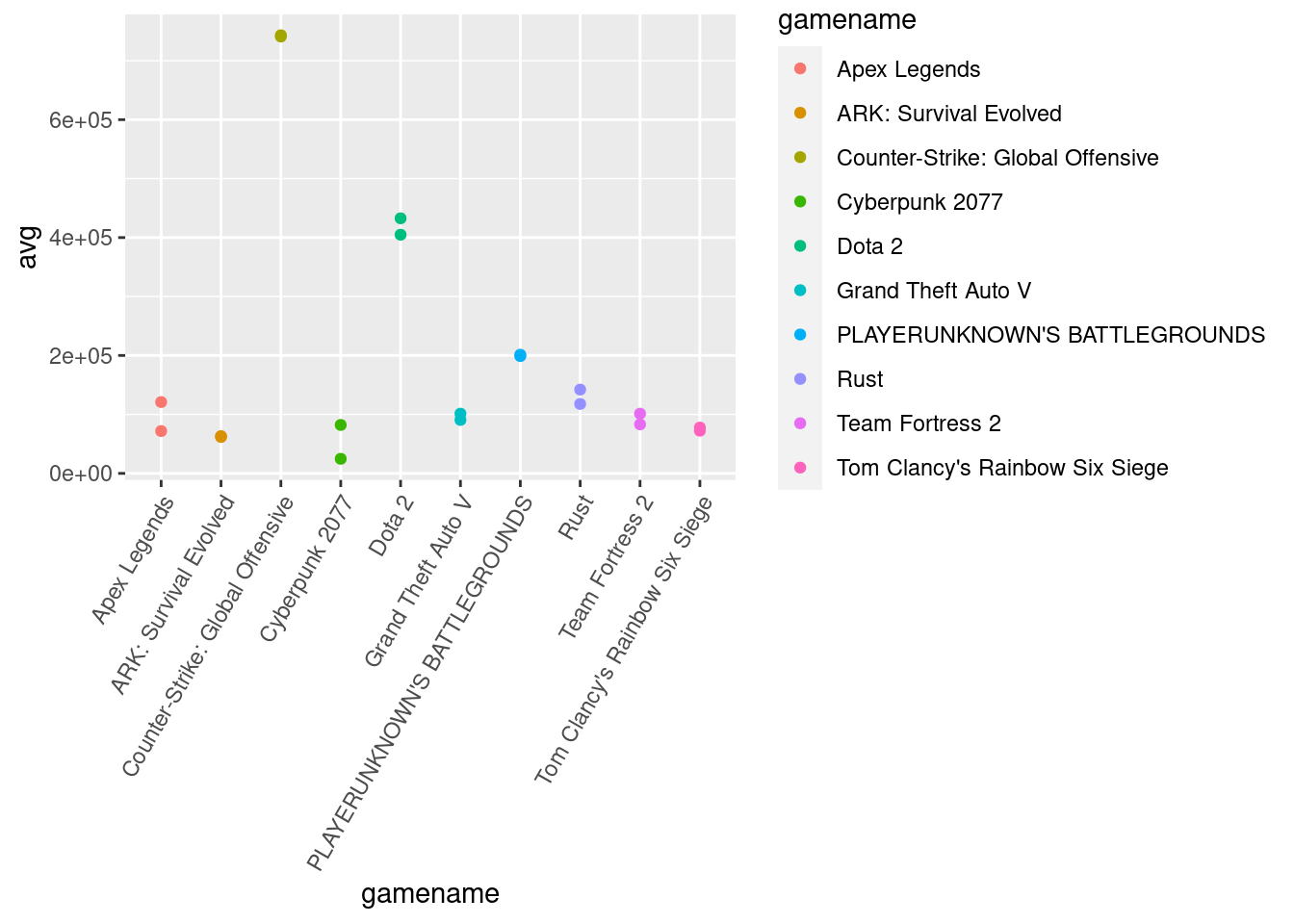
i can tell from this plot that games like apex legends,ark survival evolved,team fortress 2,cyberpunk 2077 are runners ups comparing them to the main companies like counter strike,grand theft auto,rainbow six siege and rust in the earlier part of 2021 from steams data.
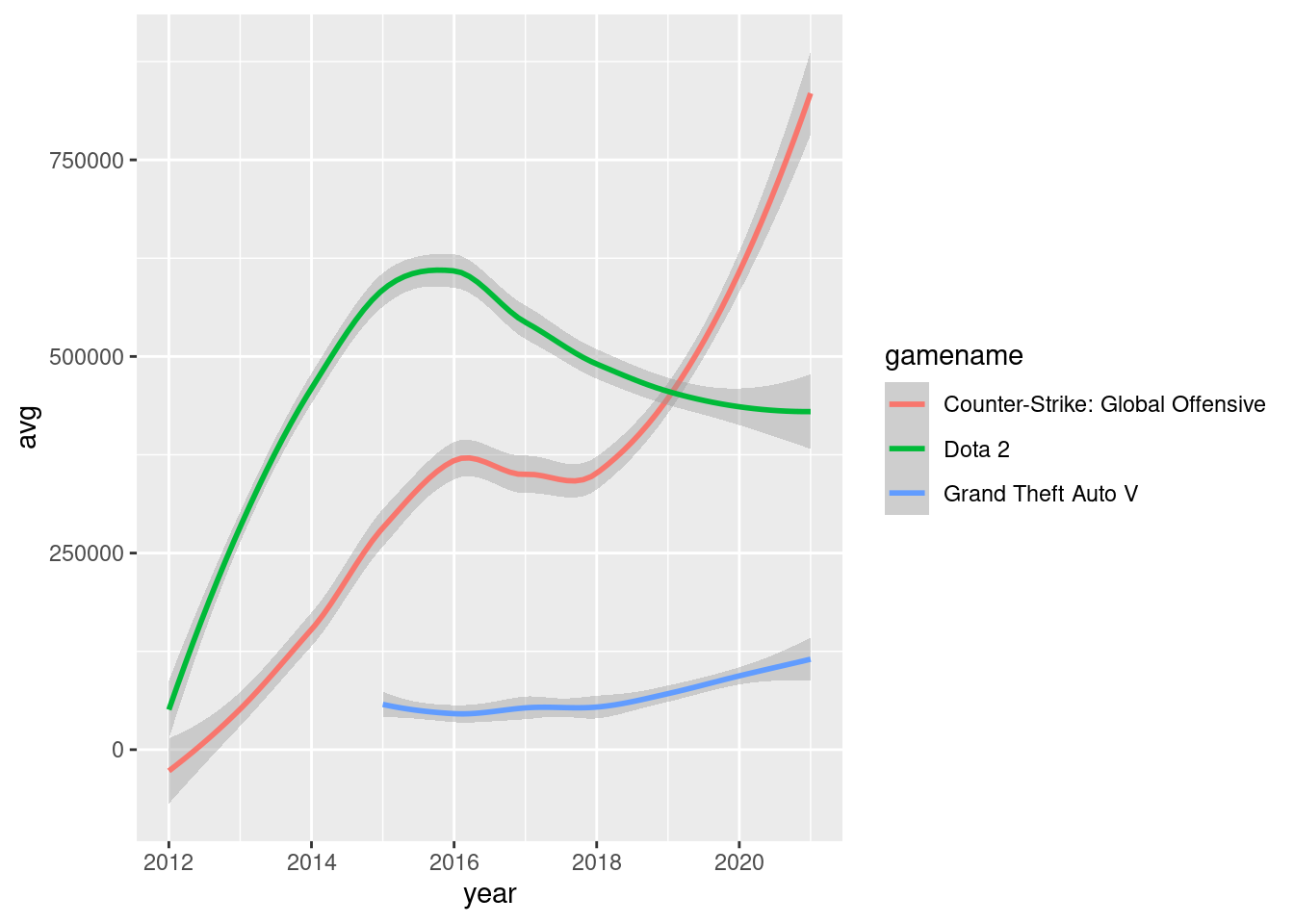
also i found that counter strike averaged way more players over the years than other games
the company names of the big companies are
-counter strike = Valve
-dota 2 = also Valve
-grand theft auto = Rockstar
-rust = facepunch
-rainbow six siege = ubisoft
Runner up companies
-apex legends = Respawn Entertainment
-team forttress 2 = Valve
-ark survival evolved = Studio Wildcard
-cyberpunk 2077 = CD Projekt Red
- What did you find out in regards to your original question?
that the big companies could own alot more than i thought,the runner ups have been making waves in the gaming community
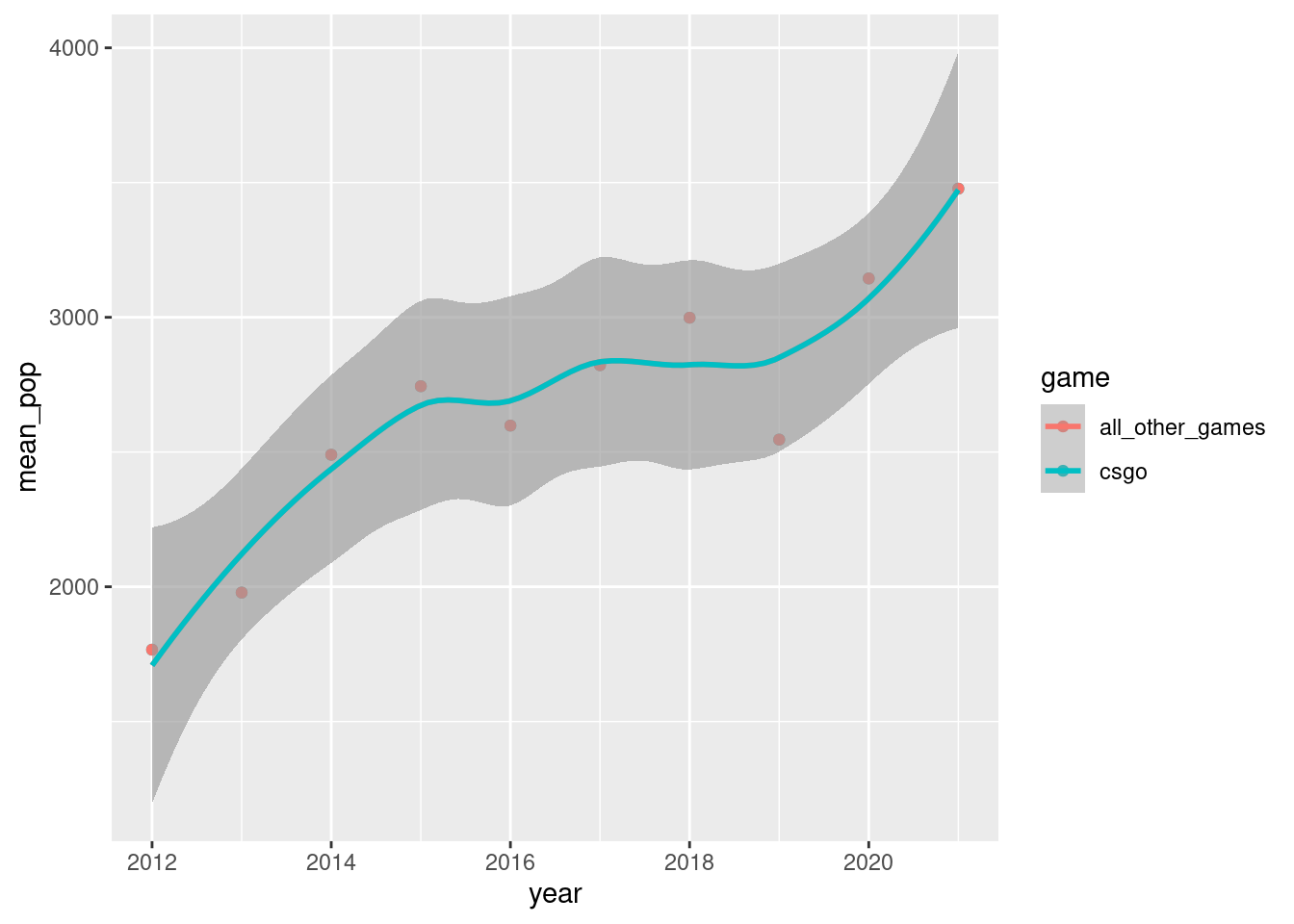
csgo has only been the leading game in players sense 2019
- What exceptions or caveats do you have in regards to your analysis you did?
that this data is only part of a small portion of 2021, and this is data only from a website called steam
that this data is not current data
- What follow up questions do you have?
i wonder what games are peaking right now on the charts, i also wonder if some of these games are still pulling that many people